


この前の記事の続きです。

英語学習でデータサイエンスを活用しようとしてまして、前回の記事で重要な構文をAnkiに登録することに成功しました。
文法の学習にもデータサイエンスを活用したいなと思っていろいろ試してみたので今回はそれについて書こうと思います。
まず私は英文法の学習のために書籍を購入しました。こちらです。
この文法書を最初から読んでいったのですが、ただ読むだけでは身についている感じが全くせず、すぐに挫折しました。
そこでこの文法書とデータサイエンスを活用して効率的な学習ができないか模索しました。
音声ファイルからテキストを抽出
キンドルで購入した書籍はPDFと違い、そのままChatGPTやGeminiにアップロードすることができません。
そこで目をつけたのは、文法書に付属している音声ファイルです。
文法書には多くの場合、英語の例文の音声ファイルが付属しています。
この音声ファイルをテキスト化し、音声ファイルと合わせてAnkiアプリに登録することでアウトプット重視の学習ができるのではと考えました。
完成形のイメージとしては、暗記カードの表面に英文とその音声を登録し、裏面に日本語訳とその英文の文法の簡単な解説を登録する感じです。
「音声ファイルの英文の理解=文法の理解」であり効率的な学習になると思いました。
最初のフェーズとして、OpenAIが公開しているWhisperという高性能な文字起こしAIを活用して、音声をテキスト化しました。
ここでもコードの実行環境としてはGoogle Colabを利用しました。
コードは当然生成AIに書いてもらいました。
この書籍の音声は英語の後に日本語が流れる形式だったので、英語と日本語を適切に分離して、それぞれテキスト化したうえでCSVファイルとして出力するようにします。
日本語の出力結果は以下のような感じです↓
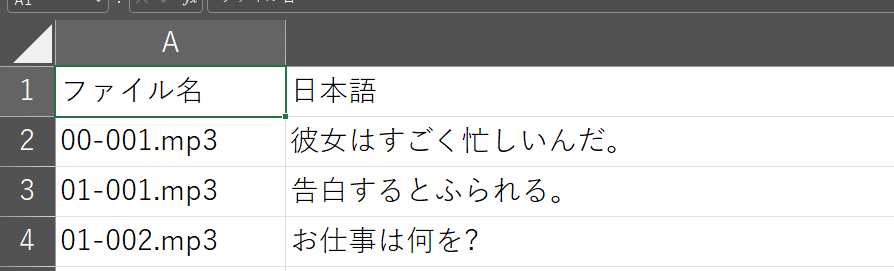
英語も同様にテキスト化しました。
この作業では、正確に日本語と英語を分離してテキスト化するのに苦労しました。
日本語の漢字変換が誤っていたり、英語も日本語としてカタカナ表記になったりと試行錯誤を繰り返しました。

英語と日本語の音声ファイルから英文のみの音声ファイルを作成
次に、Ankiに登録する音声ファイルを作成します。
もともとの音声ファイルは英語後に日本語が流れます。日本語は不要なので、英語のみの音声ファイルに変換しました。
この作業でも英語と日本語を適切に分離する必要があります。
最終的に英語と日本語の間の無音の時間で英語と日本語の境目を特定し、英語のみの音声ファイルを作成することに成功しました。
こんな感じで音声ファイルが出力されます↓
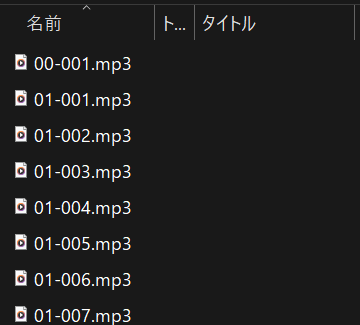
英文の文法の解説を作成
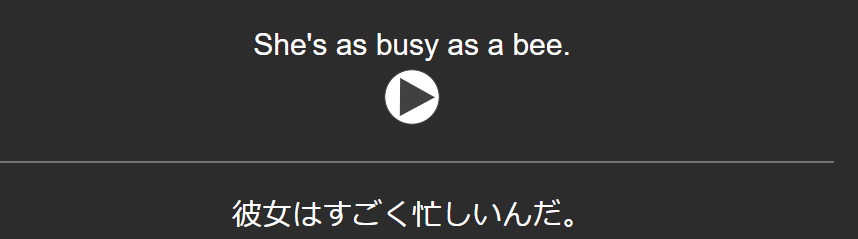
先ほどの作業でテキスト化した英語・日本語と、音声ファイルを使って一度Ankiに登録してみました。こんな感じ↓
ただ、Ankiをやっていると、どのような文法を使っているのか理解できない英文がありました。
そのような場合に文法書を確認するのは手間なので、文法の簡単な解説もAnkiに登録することを決意しました。
これは結構頭を悩ませましたが、最終的にOpenAIのAPIを利用することにしました。1,000円くらい課金しました。
簡単に言うとAIを使って大量の英文の文法の解説をまとめて作成する感じです。
PythonのコードでAPIを利用することで以下のように文法の解説付きのCSVファイルを作成しました。こんな感じです↓
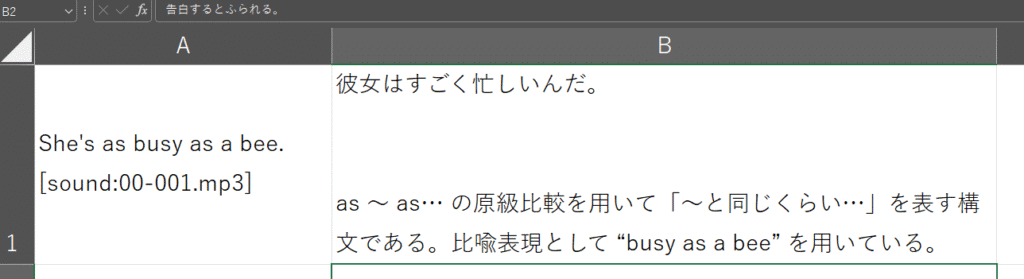
このCSVファイルをAnkiに登録することで、英語の音声を聞きながら文法を学べる暗記カードが完成しました。

この文法の解説は結構精度が高く感動しました。
学習効率が明らかに高くなると思います。
あとはこの暗記カードを繰り返すだけで文法が身につくはずです。(まったくやってない。)
続く。


コメント